APP活跃统计管理
APP活跃统计管理用于统计和分析应用的活跃情况,数据来源于集成了我们SDK的应用。
快速访问
在APP活跃统计管理模块中,您可以快速访问系统。
- 功能入口:数据分析 -> APP活跃统计管理
- 直接访问:点击跳转到APP活跃统计管理
功能说明
APP活跃统计管理的功能说明:该模块主要用于查看特定APP的活跃数据统计,帮助您了解哪些应用被用户频繁使用。
1. 活跃统计列表(一级页面)
APP活跃统计的一级页面:在APP活跃统计管理的一级页面中,这里展示了APP的整体活跃情况。数据是根据预设的定时任务(或手动触发)按年、月、日维度汇总得出的结果。
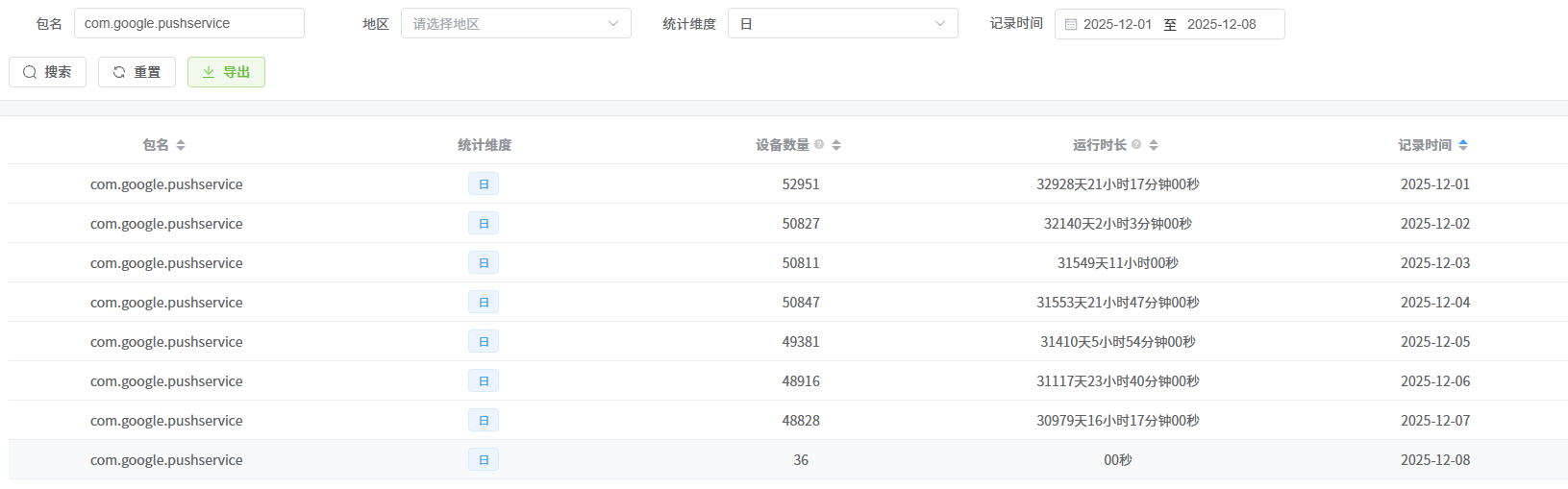
操作说明:您可以通过上方的搜索框,输入APP名称、包名,选择统计维度、记录时间来查找特定的应用。
字段说明:
- 包名:APP的包名。
- 统计维度:含年、月、日三种类型。
- 设备数量:截止统计任务执行时,对应统计维度(年、月、日)下的设备总数。
- 运行时长:截止统计任务执行时,对应统计维度(年、月、日)下所有设备的累计运行时长。点击数值可切换显示格式。
- 记录时间:对应统计维度(年、月、日)的具体时间点。
数据导出:
- 同步导出:点击导出后,系统立即处理并返回导出结果。
2. 详细活跃数据(二级页面)
APP活跃统计的二级页面:在APP活跃统计管理的二级页面中,点击列表中的某一项,可进入二级页面查看每一台设备的详细活跃数据。这些数据同样基于定时任务统计分段数据生成。
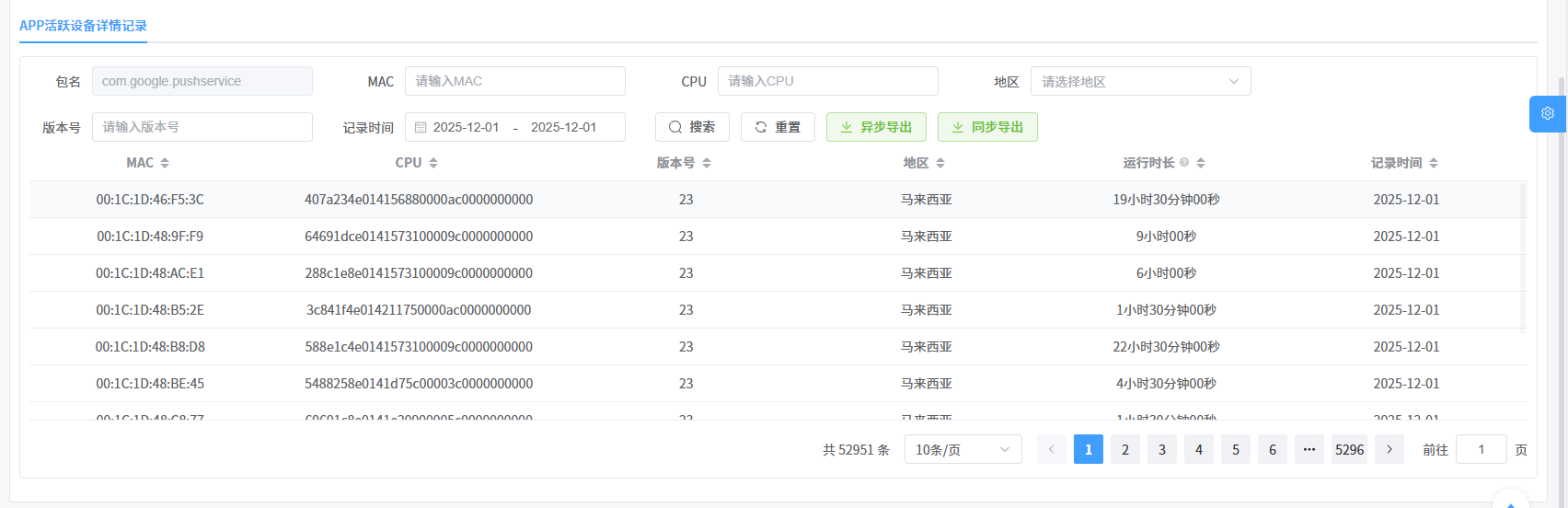
功能:
- 列表查询:查看具体的活跃记录,支持按包名、MAC地址、CPU、地区及APP版本号进行搜索。
- 导出:点击“导出”按钮,可将当前的活跃统计数据导出为Excel文件,便于离线分析。
字段说明:
- MAC:设备的MAC地址。
- CPU:设备的CPU。
- 版本号:APP的版本号。
- 地区:设备所属地区。
- 包名:APP的包名(由上一级页面带入,列表默认隐藏)。
- 统计维度:统计的时间维度(年/月/日)(由上一级页面带入,列表默认隐藏)。
- 运行时长:设备的APP运行时长。点击数值可切换显示格式。
- 记录时间:对应统计维度(年、月、日)的具体时间。

数据导出:
- 同步导出:点击导出后,系统立即处理并返回导出结果。
- 异步导出:当数据量较大时,系统采用异步导出方式。您可以在 导出任务管理模块 中查看进度并下载文件。
常见问题
APP活跃统计管理的常见问题:关于APP活跃统计管理的常见问题:
- 数据更新频率:数据更新取决于统计任务的执行时间,通常为每日更新。
当导出数据量较大时,系统会采用异步导出方式。您可以在 导出任务管理 中查看导出进度并下载文件。
技术实现
本章节详细说明APP活跃统计的后端技术实现,包括数据上报、消息队列处理、分表策略及定时任务调度。
1. 核心架构与数据流向
系统采用 API上报 -> Kafka缓冲 -> 原始日志分表存储 -> 定时任务ETL聚合 的架构模式,以支持高并发的设备活跃数据上报。
2. 数据上报接口
APP端通过API上报活跃数据,后端根据接口版本和上报类型采取不同的处理策略,代码参考 ForeignThirdAppApiController.java。
详细接口定义、参数说明及三种上报模式(实时/延迟/特殊)请参考:APP 活跃上报接口
-
V1 接口 (
/app/activity):- 采用直接入库模式,适用于低频或老版本客户端。
- 数据经过清洗(MAC格式化、IP解析地区)后直接写入活跃详情表。
-
V2 接口 (
/third/app/activity/v2):- 实时模式:设备按服务端配置间隔上报,服务端通过 Kafka 异步处理。
- 延迟模式 (
TYPE_DELAY):设备批量上报历史积压数据,后端跳过 Kafka 直接入库。 - 特殊模式:设备仅上报活跃状态(如开机、跨天),不统计运行时长。
3. 数据处理与存储
Kafka 消费
消费者 AppActivityConsumer.java 订阅 app-activity Topic,将接收到的 AppActivityReq 数据写入原始日志表。
动态分表策略
为了应对海量日志数据,系统采用了日期+包名的分表策略,并结合Hash分区:
- 表名规则:
app_activity_log_{yyyyMMdd}_{packageName} - 分区策略:基于
partition_index(MAC+CPU Hash取模) 进行表内分区,提高查询效率。
4. 定时任务 (XXL-JOB)
系统通过 AppActivityJob.java 维护两个核心任务:
-
分表管理 (
appActivityCreateTable):- 自动创建未来 N 天的原始日志表。
- 自动清理 N 年前的过期日志表��。
-
数据ETL聚合 (
appActivityLogToDetail):- 按日读取原始日志表数据。
- 聚合计算后转存至活跃详情表(供前端查询展示)。
- 记录任务耗时,监控处理性能。
5. 数据模型关系
下图展示了从原始日志上报到最终统计数据的逻辑转换关系: