APP运行记录管理
APP运行记录管理用于记录和查询设备上所有应用的详细运行情况,包括运行时长、打开次数等。
数据由设备按日汇总上报(隔天上传),涵盖所有非系统APP的运行数据。此外,支持通过事件上报接口(/task/recoedDeviceEvent)接收设备上报的实时运行记录(事件类型:APP_RUNTIME)。如遇到第二日设备未开机或无网络等异常情况,则会再下一次网络恢复后上报所有积累的数据。
快速访问
在APP运行记录管理模块中,您可以快速访问系统。
- 功能入口:数据分析 -> APP运行记录管理
- 直接访问:点击跳转到APP运行记录管理
功能说明
1. 运行记录概览(一级页面)
在APP运行记录管理的一级页面中,数据是根据预设的定时任务(或手动触发)按月统计原始数据生成,非实时数据。

操作说明:
- 支持通过 APP名称、包名 进行搜索。
- 可选择 记录时间(月) 和 是否按版本号分组 来查找特定的APP运行记录。
字段说明:
- 包名:APP的包名。
- 版本号:APP的版本号(仅当查询条件中“是否按版本号分组”选择“是”时显示)。
- APP名称:APP名称(来源于 app安装列表)。
- 设备数量:截止统计任务执行时,对应月份的设备总数。
- 平均时长:截止任务执行时,对应月份的平均每台设备运行时长(打开时长 / 设备总数)。
- 打开时长:所有设备运行时长之和。
- 记录条数:对应月份的记录总条数。
- 打开次数:对应月份的总打开次数。
数据导出:
- 同步导出:点击导出后,系统立即处理并返回导出结果。
-c4db9739bc34182ddc2462206fd75a51.png)
2. 详细记录(二级页面)
在APP运行记录管理的二级页面中,点击一级列表中的条目,可以进入查看详细的运行记录(实时数据)。 数据由设备按日汇总上报(隔天上传)。
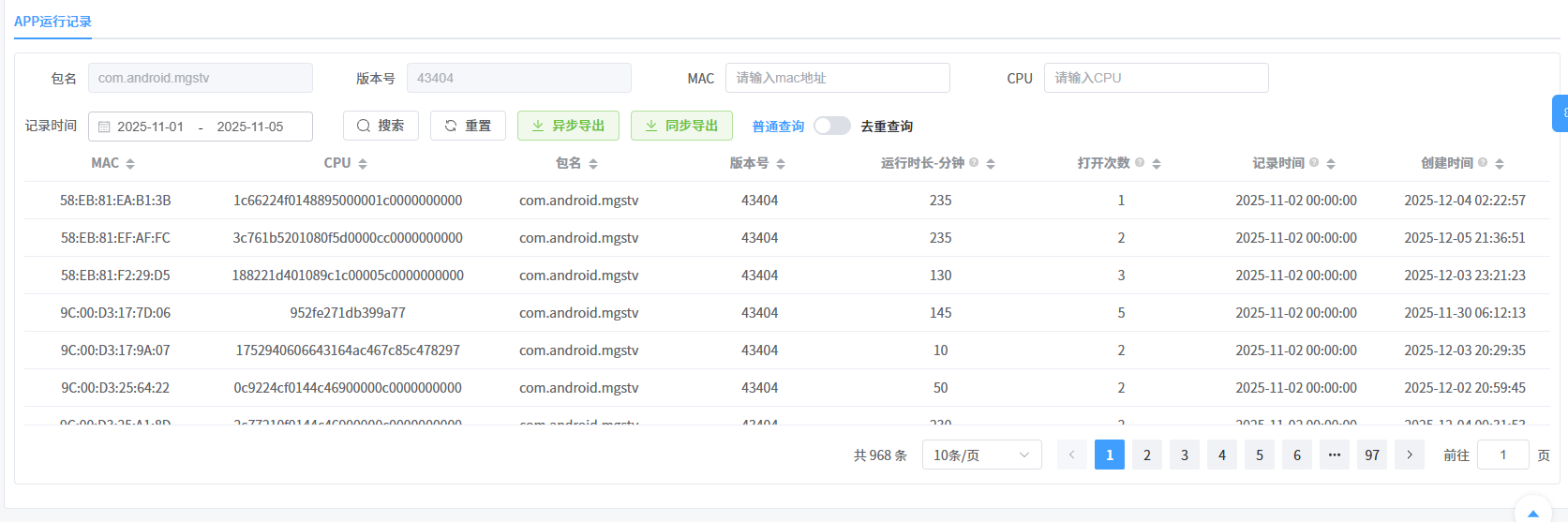
操作说明:
- 支持通过 MAC、CPU 进行搜索。
- 可选择 记录时间(日期范围) 来查找特定的APP运行记录。
列表字段说明:
- MAC/CPU:设备唯一标识。
- 包名/版本号:APP信息。
- 运行时间:当日设备的运行时长。
- 打开次数:当日设备的打开次数。
- 记录时间:APP运行的日期。注意:这是设备端自行统计的时间。
- 创建时间:服务器实际��收到设备上报该条数据的时间。
特殊查询(按设备去重):可以查看去重后的数据(正常每月一天一条,去重后只算一条)。
-751da6b7181a69216c34da9f9e5d799c.png)
数据导出:
- 同步导出:点击导出后,系统立即处理并返回导出结果。
- 异步导出:当数据量较大时,系统采用异步导出方式。您可以在 导出任务管理模块 中查看进度并下载文件。
![]()
技术架构与数据流
本模块涉及从设备端上报、Kafka消息消费、TDengine时序数据库存储、MySQL元数据管理到XXL-JOB定时统计与归档的全链路流程。
1. 数据流向图
以下是APP运行记录从采集到存储、统计及归档的完整数据流向。数据可以通过设备按日汇总上报,也可以通过实时事件(APP_RUNTIME)上报,两者最终汇入同一个 Kafka Topic 进行统一处理:
2. 数据模型关系图
主要涉及的数据实体及其关系如下:
核心业务逻辑
1. 数据入库与校验 (AppRuntimeConsumer)
数据通过Kafka消费者 AppRuntimeConsumer 进行处理。
数据源说明:
- 按日汇总:设备端每日定时上传前一天的运行记录。
- 事件上报:设备端通过
/task/recoedDeviceEvent接口上报APP_RUNTIME事件,由DeviceEventService接收并转发至app-runtime-listTopic。
AppRuntimeConsumer 对上述两种来源的数据执行统一的处理逻辑:
- 数据过滤:
- 时长校验:过滤掉运行时长不在允许范围内(
MIN_DURATION~MAX_DURATION)的异常数据。 - 时间有效性校验:
- 过滤掉超过保留期限(配置
AppRuntimeWriteKeep)的旧数据。 - 过滤掉未来时间的数据(允许一定误差)。
- 过滤掉超过保留期限(配置
- 时长校验:过滤掉运行时长不在允许范围内(
- 包名管理:调用
AppPackageNameUtil.quickInsert自动将新出现的包名录入系统。如果该包名被配置为“不统计”(isUseAppRuntime=false),则丢弃该条记录。 - 任务关联(关键逻辑):
- 系统会自动检查该设备是否存在针对该APP的推送任务(
TaskDeviceDO)。 - 如果存在推送任务且状态为“推送成功”,但尚未收到运行反馈,系统会将当前运行记录的时间更新到任务状态中(
appRuntimeReportDeviceTime),标志着该APP不仅被成功推送到设备,且已被用户实际运行。
- 系统会自动检查该设备是否存在针对该APP的推送任务(
- 数据存储:通过
AppRuntimeTopService将清洗后的数据写入 TDengine 热数据表。
2. 统计分析 (AppRuntimeJob)
统计任务 appRunTopAnalysis 通过 XXL-JOB 定期执行(通常按月),逻辑如下:
- 冷热数据智能路由:
- 如果统计月份为当前月或上个月(距今 <= 1个月),系统自动查询 TDengine热表。
- 如果统计月份为历史月份,系统自动切换查询 TDengine归档表。
- 分批处理:
- 任务支持传入指定包名列表进行“单包分析”。
- 若未指定,则扫描所有已注册包名,按批次(如每批50个)进行并行统计,避免内存溢出。
- 统计维度:
- 计算指定月份内,每个APP的设备覆盖数、总运行时长、总打开次数。
- �统计结果存入 MySQL 的
app_runtime_top表,供前端一级页面快速查询。
- APP名称修正:另有任务
appRuntimeSetAppname会定期检查统计表,确保APP名称与最新包名库保持一致。
3. 数据归档 (AppRuntimeArchiveJob)
为了解决时序数据库处理“乱序数据”时的存储膨胀问题,系统设计了严密的归档流程:
- 触发机制:XXL-JOB 任务
appRuntimeArchive,读取配置决定归档日期区间。 - 归档流程:
- 检查状态:查询
app_runtime_archive_record表,跳过已成功归档的日期。 - 脚本下发:自动将备份脚本 (
app_runtime_backup.sh) 和恢复脚本 (app_runtime_restore.py) 上传至 TDengine 服务器。 - 数据备份:执行 Shell 脚本,按天将热数据导出为 CSV 并压缩为 ZIP。
- 有序重写:执行 Python 脚本,将备份数据解压,并按时间有序的方式批量插入到归档库。
- 状态记录:根据脚本执行结果,更新归档记录表的状态(成功/失败)、插入条数及错误信息。
- 检查状态:查询
- 容错机制:支持自动重试过去N天内失败的归档任务。
数据归档与存储策略
为了保证系统的查询性能和存储效率,APP运行记录数据采用了冷热分离的存储策略。详细的技术背景请参考 TDengine 乱序插入压缩问题。
- 热数据保留期:系统仅在高性能热数据库中保留最近 45天 的数据。
- 自动归档:超过45天的历史数据,会通过后台任务自动迁移至归档数据库。
- 查询影响:
- 近期数据:查询最近45天内的数据时,响应速度极快。
- 历史数据:如需查询45天前的历史数据,系统会自动切换至归档库查询,查询响应时间可能会略有增加。
归档原理
归档简要数据流向
归档架构设计
整体流程由 XXL-JOB 调度中心发起,通过 SSH 远程调用部署在 TDengine 节点的 Shell 和 Python 脚本,完成数据的导出、压缩与重写入。
核心归档逻辑
步骤一:按天导出与压缩 (Backup)
使用 app_runtime_backup.sh 脚本,利用 TDengine 的 SELECT ... >> file.csv 功能,按 day 字段(时间分片)将热数据导出。
- 按天隔离:每次只导出一个自然日的数据,确保数据在时间维度上的纯净性。
- 即时压缩:导出完成后立即调用
zip压缩,大幅减少中间文件的磁盘占用(压缩比通常极高)。
# 伪代码示例
taos -s "SELECT ... FROM flow_app_runtime WHERE day = 20251001 >> app_runtime_20251001.csv"
zip app_runtime_20251001.zip app_runtime_20251001.csv
rm app_runtime_20251001.csv
步骤二:有序批量重写 (Restore)
使用 app_runtime_restore.py 脚本将备份数据写入归档库。
- 多线程并发:开启多个线程(如 10 个)并行处理不同日期的数据。
- 批量写入:读取 CSV 后,每 400 条记录拼接为一个大
INSERT语句批量写入,提高吞吐量。 - 重获有序性:由于 CSV 本身是按天导出的,且在插入时是批量追加,数据在物理存储上重新获得�了“时间有序性”,从而激活了 TDengine 的列式压缩优势。
步骤三:调度策略 (XXL-JOB)
通过配置 XXL-JOB 参数灵活控制归档行为:
{
"backup": true,
"write": true,
"forceArchiveTwoMonthsAgo": true,
"archiveDayConfigs": [
{
"archiveDaysAgo": 45, // 归档 45 天前的数据
"retryLookbackDays": 10 // 自动重试过去 10 天内失败的归档
}
]
}
- 冷热分离:保留最近 45 天的热数据在线查询,45 天前的数据进入归档库。
- 自动容错:自动扫描并重试最近 10 天内状态为“失败”的归档任务。
当导出数据量较大时,系统会采用异步导出方式。您可以在 导出任务管理模块 中查看导出进度并下载文件。